How to do Web Scraping with Java and HtmlUnit?
Sometimes we need to collect data from other websites that do not have public API or do not have API endpoints for data that we need. Some common cases are that we need to collect some analytics, observe competitor's website, or we just want to automate some work. That is a perfect use-case for Web Scraping.
There are a few available Java libraries that we can use for Scraping. In this article, we will explain how to write a Java code using HtmlUnit, which will scrape some data from a website.
Prerequisites
We will rely on the following tools so make sure you install them and get familiar with them before we start:
- Java 11 or newer - how to install
- Maven or Gradle
- Some IDE editor - we will use IntelliJ IDEA Community Edition which is free
Create a project
In your IDE go to File / New / Project... and choose Maven or Gradle as a type of Java project.
If you are setting a Java project for the first time, check out this article about creating a Hello World project.
Add HtmlUnit library
We decided to use HtmlUnit because it is the most powerful Java library for Web Scraping, in case we need it later for some advanced use cases. HtmlUnit represents a headless browser that helps us with processing HTML content.
Add it to our project as a Maven or Gradle dependency:
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.50.0</version>
</dependency>Let's scrape some website
Let's say we want to scrape this DevPal website and list all online tools it offers.
Investigate the web page
In order to extract some data from a website, we first need to inspect the web page. After that we will know how to program our web scraper, from what location of the page to pull out relevant information for us.
DevPal lists all of its tools in the page footer.
Using Chrome browser we can inspect the page by doing a right mouse click and choosing Inspect menu item.
It will show us the HTML structure of the web page.
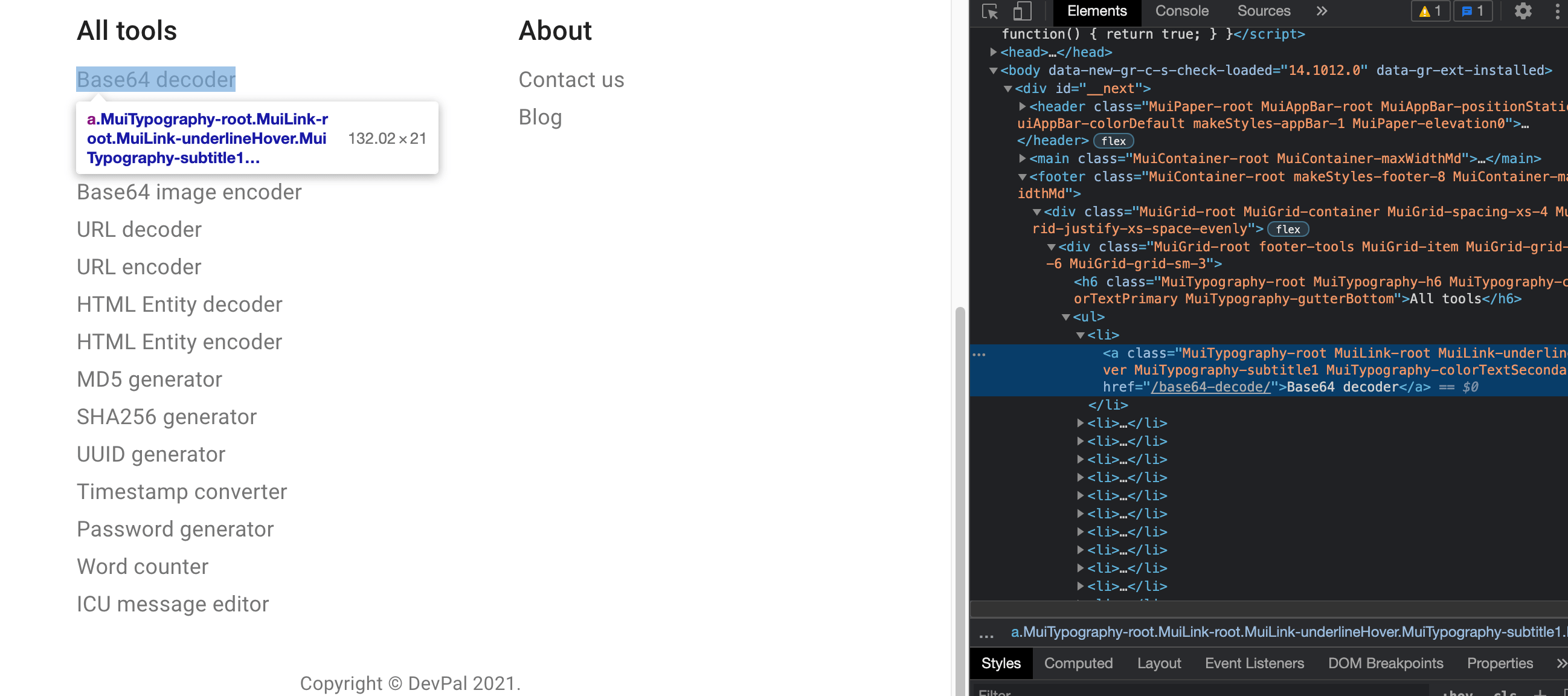
This helps us to define a unique identifier for the elements we want to scrape from the page.
We will use a CSS selector for targeting HTML elements.
A CSS selector for each tool link in our case would be footer ul li a.
The same can also be done in Firefox or any other browser.
Implement
First, fetch the web page that has relevant information for scraping
WebClient client = new WebClient();
HtmlPage page = client.getPage("https://devpal.co");Then, get all HTML elements with relevant information.
We can get elements in a few different ways. Here are the most common:
- page.querySelectorAll(".footer-tools ul li a") - A flexible way to target any visible elements. We will use this approach.
- page.getHtmlElementById("element-id") - Useful for targeting a single element, if it has assigned ID.
- page.getByXPath(".//meta[@name='description']") - Useful when we want to target non visible, meta elements of a web page.
The query will return a list of generic DOM elements:
DomNodeList<DomNode> domNodes = page.querySelectorAll(".footer-tools ul li a");Since we know those are anchor type of elements (marked with <a> tags) we can iterate through them and cast them to HtmlAnchor objects.
We can get the tool name from the anchor element text, and tool link from the anchor's href="..." attribute. The link is relative, so we will append it to the domain in order to get the full, absolute URL.
for (DomNode domNode : domNodes) {
HtmlAnchor htmlAnchor = (HtmlAnchor) domNode;
System.out.println("Tool: " + htmlAnchor.getTextContent());
System.out.println("Link: https://devpal.co" + htmlAnchor.getHrefAttribute());
System.out.println();
}
Here is a complete Java class that does the work and prints the result to the console:
package co.devpal;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.DomNode;
import com.gargoylesoftware.htmlunit.html.DomNodeList;
import com.gargoylesoftware.htmlunit.html.HtmlAnchor;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import java.io.IOException;
public class DemoScraper {
public static void main(String[] args) throws IOException {
WebClient client = new WebClient();
HtmlPage page = client.getPage("https://devpal.co");
DomNodeList<DomNode> domNodes = page.querySelectorAll(".footer-tools ul li a");
System.out.println("Total tools found: " + domNodes.size());
System.out.println();
for (DomNode domNode : domNodes) {
HtmlAnchor htmlAnchor = (HtmlAnchor) domNode;
System.out.println("Tool: " + htmlAnchor.getTextContent());
System.out.println("Link: https://devpal.co" + htmlAnchor.getHrefAttribute());
System.out.println();
}
}
}
Conclusion
In the given example we saw how to scrape a web page and extract some data. The example can be extended by scraping multiple web pages and exporting the data to some file formats, such as JSON or Excel.